Projects
A selection of projects built independently and through portfolio-focused work that reflect how I approach real-world data and software problems. These systems emphasize engineering judgment, correctness, and thoughtful trade-offs across data pipelines, backend services, and cloud-native architectures.
They are designed to demonstrate patterns and decision-making rather than polished product demos or large-scale enterprise deployments.
Wistia Video Analytics Pipeline (Portfolio Project)
Fully automated AWS-native data pipeline delivering daily video analytics insights from Wistia for marketing analysts through a medallion architecture lakehouse.
Marketing and product teams rely on video analytics to decide what to improve, but raw event data can silently drift or break and lead to misleading conclusions.
The biggest focus here was correctness over time: building confidence that “today’s numbers” were complete and comparable to yesterday’s, even as upstream API behavior and data shapes evolved.
The platform ingests Wistia media and visitor statistics via API, processes them through Bronze/Silver/Gold layers using PySpark, and exposes analytics-ready data through Athena.
Technologies Used
Key Highlights
Engineering Outcomes
- →Demonstrated deterministic ingestion across paginated API endpoints
- →Validated daily correctness boundaries across multiple media IDs
- →Implemented idempotent reprocessing using explicit state tracking
- →Designed CI/CD safety gates to prevent silent ingestion regressions
Walmart Sales Analytics & Visualization Pipeline
Analytics engineering project demonstrating how curated warehouse data can be queried, transformed, and visualized programmatically using Python and SQL.
Retail performance is influenced by external factors like fuel prices, inflation, unemployment, and seasonal effects. This project demonstrates how curated datasets can be combined to explore those relationships and surface useful business insights.
The main challenge was analytical clarity: aligning datasets with different granularities and update cadences without creating accidental correlations or misleading conclusions.
The analytics workflow retrieves curated data slices from Snowflake using SQLAlchemy, then transforms and visualizes them with Pandas and Plotly to support exploratory analysis.
Technologies Used
Example Outputs
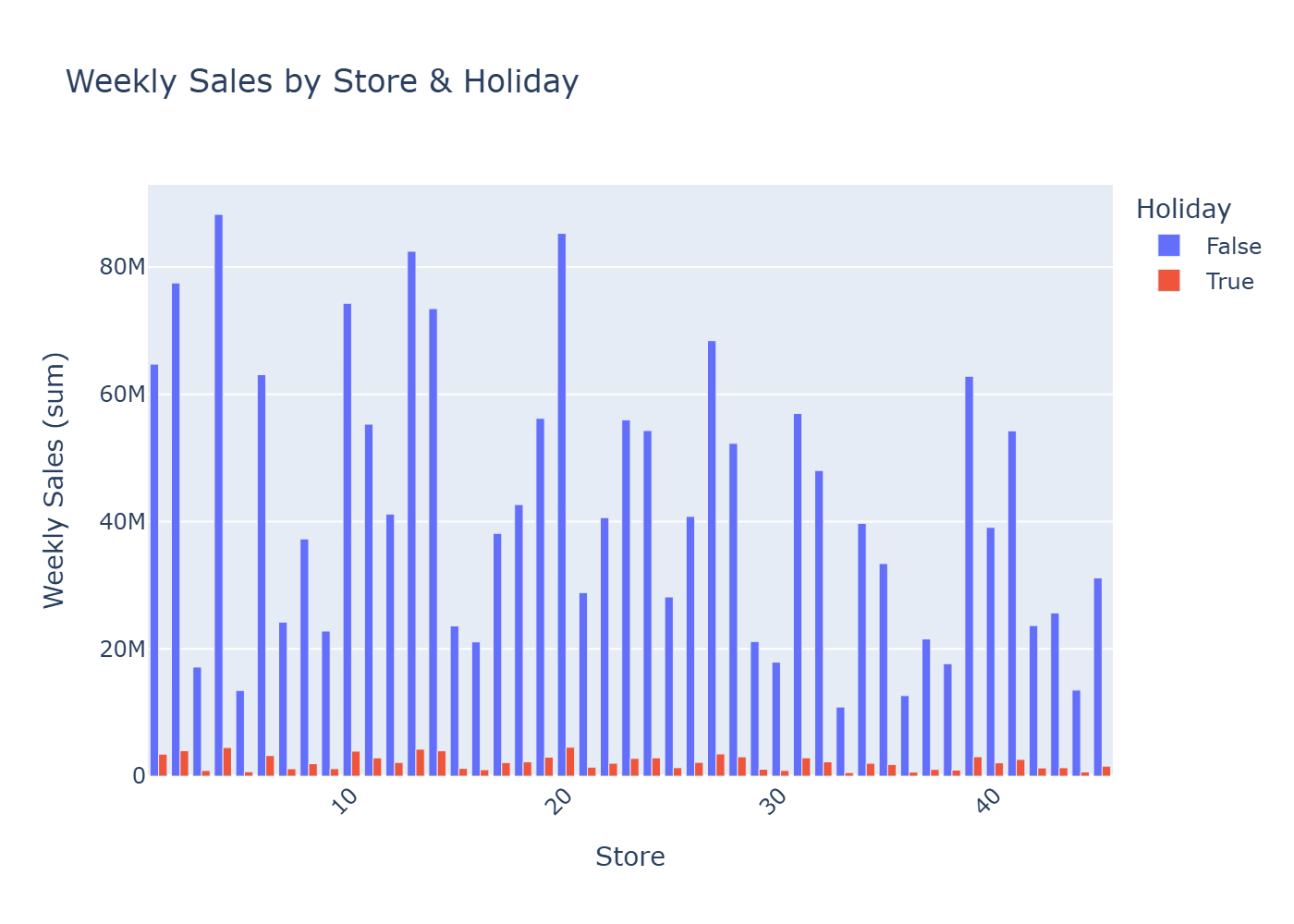
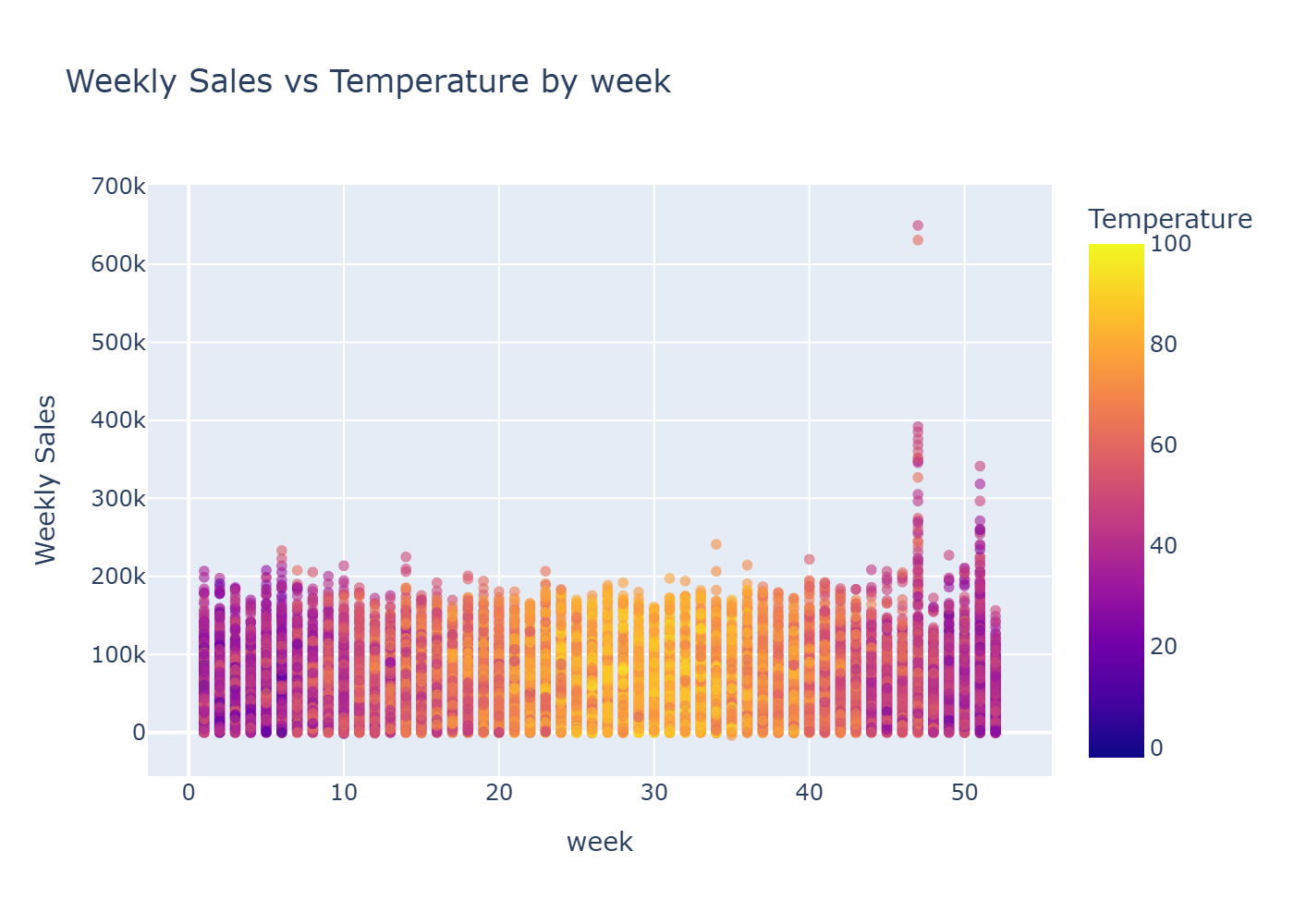
Key Highlights
Engineering Outcomes
- →Created reusable analytics template for warehouse consumption
- →Enabled visual exploration of multi-factor sales trends
- →Demonstrated end-to-end analytics engineering workflow
- →Validated warehouse data quality through exploratory analysis
Event-Driven CRM Lead Capture Pipeline (Portfolio)
Serverless event-driven pipeline automating CRM lead ingestion, enrichment with owner data, and real-time Slack notifications for sales operations.
Sales teams need lead events routed quickly and consistently, but webhook-driven systems can become noisy, duplicate events, or fail silently if not designed carefully.
The biggest focus was responsiveness with correctness: processing events quickly while preventing duplicates, handling eventual consistency, and maintaining clear failure paths.
The pipeline captures webhook events through API Gateway, buffers them in SQS for delayed enrichment, and publishes enriched notifications to Slack.
Technologies Used
Key Highlights
Engineering Outcomes
- →Demonstrated event-driven ingestion using webhooks and serverless components
- →Implemented delayed enrichment using SQS to handle eventual consistency
- →Designed idempotent processing to prevent duplicate notifications
- →Explored error classification and retry strategies in distributed workflows
Healthcare Staffing Analytics Pipeline (PoC)
Proof-of-concept data pipeline exploring schema normalization, data quality enforcement, and analytics modeling for healthcare staffing datasets.
Operational decisions in healthcare depend on staffing and census metrics being consistent and explainable. This project turns messy daily CSV inputs into analytics-ready datasets that can be queried with confidence.
The biggest focus was correctness and traceability: enforcing schema consistency across irregular source files and making it clear when data was safe to trust.
The pipeline ingests daily staffing and census CSVs, validates schemas, joins PBJ and provider datasets in Spark, and produces analytics-ready aggregates.
Technologies Used
Example Outputs
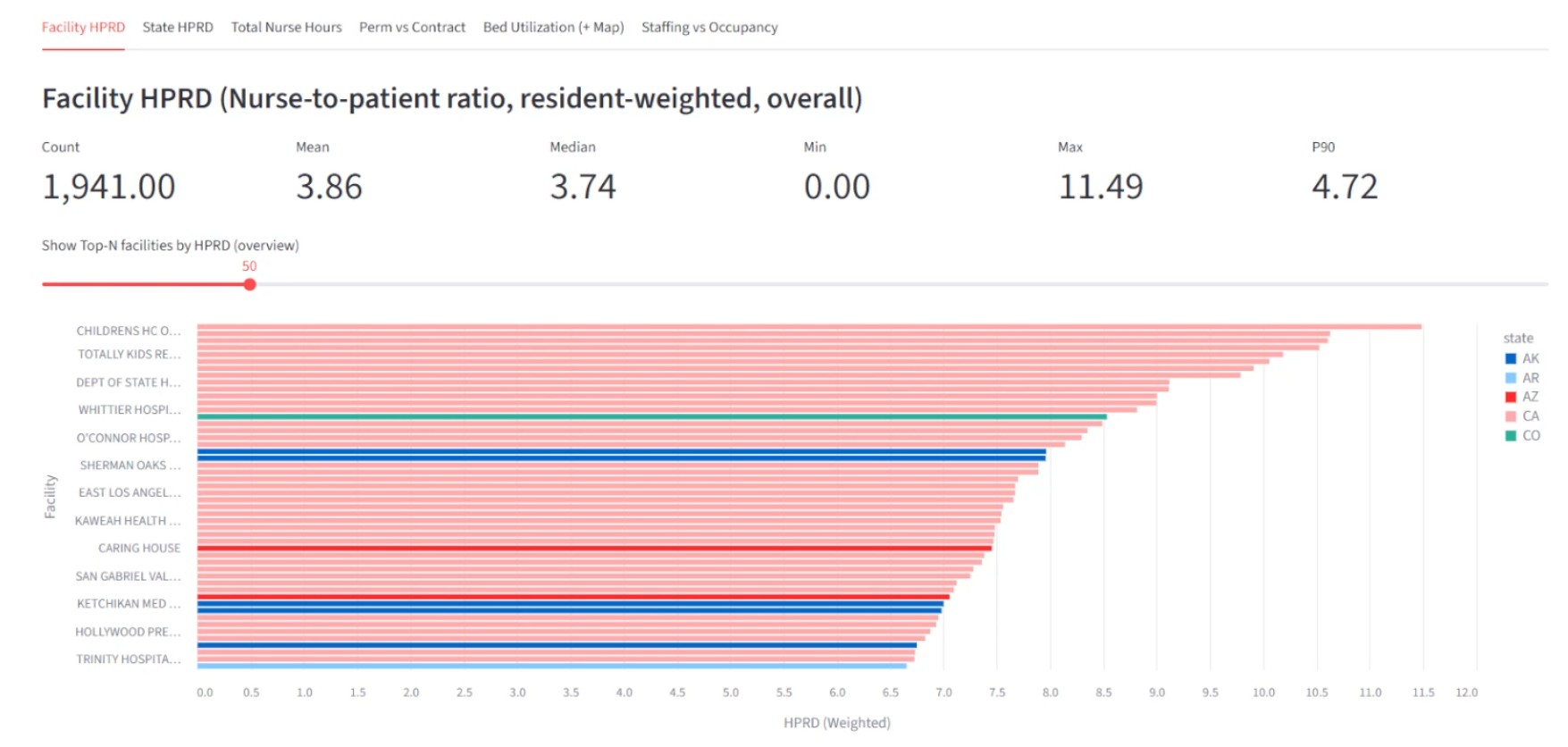
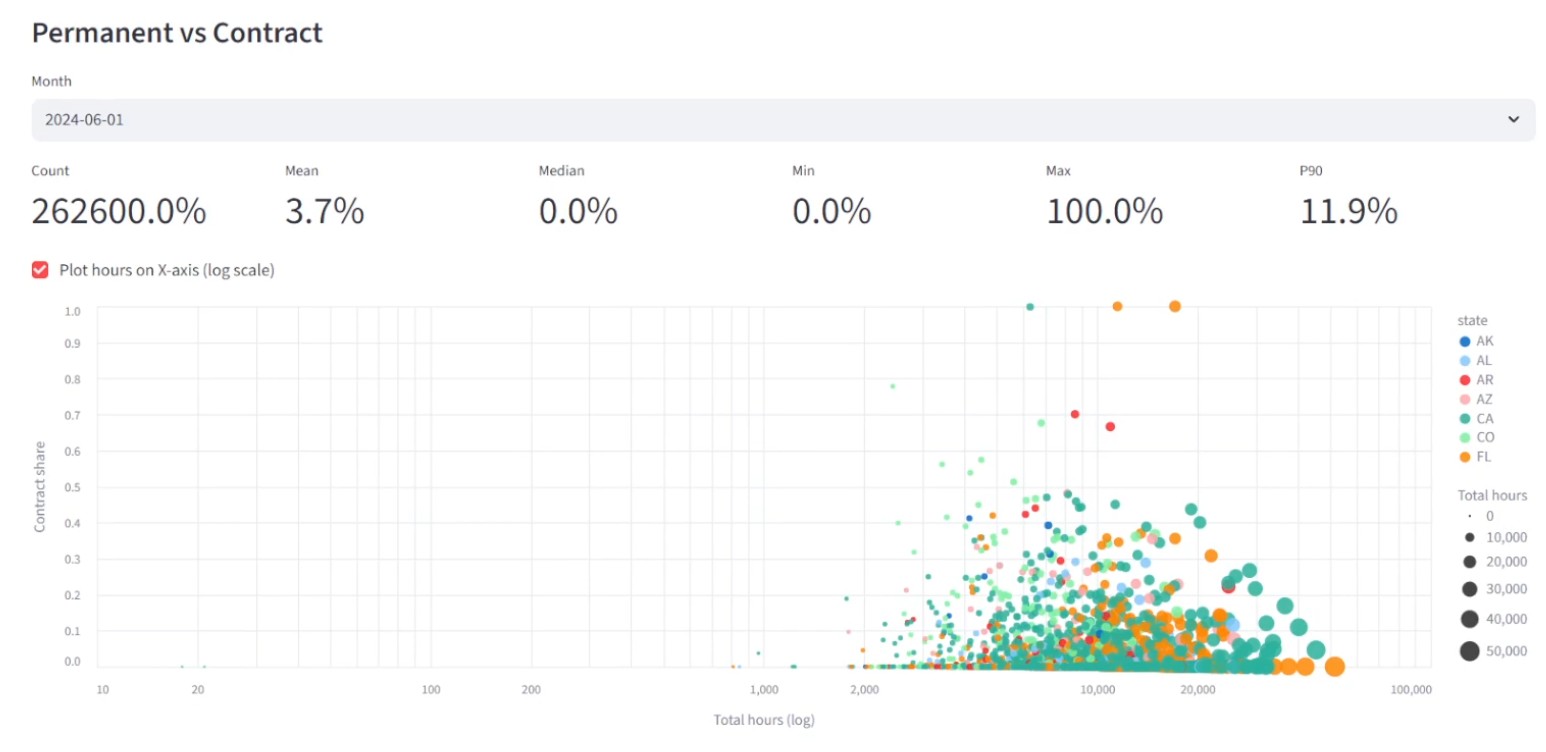
Key Highlights
Engineering Outcomes
- →Validated schema reconciliation strategies across heterogeneous CSV inputs
- →Demonstrated medallion-style layering for correctness and replayability
- →Explored dimensional modeling approaches for staffing analytics
- →Identified data quality risks common in healthcare operational reporting
Telecom Automation Platform
Comprehensive test automation and orchestration framework for complex telecom distributed systems with CI/CD integration.
Telecom systems are complex, distributed, and high-availability—changes need fast feedback without risking reliability. This work focused on building automation that made releases safer and debugging faster.
The biggest focus was reliability and feedback speed: reducing manual effort while increasing confidence that deployments behaved correctly in real environments.
Built automation frameworks for testing and deploying telecom systems, including environment orchestration, diagnostics, and monitoring utilities. Developed test harnesses and CI/CD workflows that improved repeatability and reduced the time needed to detect and isolate failures in distributed systems.
Technologies Used
Key Highlights
Engineering Outcomes
- →Improved deployment reliability through automated testing and CI/CD
- →Enabled faster feedback cycles for distributed system changes
- →Reduced manual debugging effort through custom diagnostics
- →Supported continuous delivery practices in complex system environments
SaaS Product Development
Complete SaaS product built from concept to production including backend API, authentication, billing, and containerized infrastructure under own LLC.
mySatchel.app is a SaaS tool built to replace fragile spreadsheets with a purpose-built system for managing formulation calculations reliably.
The biggest challenge was balancing delivery with scope: making practical trade-offs so the product could ship and evolve while still maintaining a clean foundation.
The application exposes RESTful APIs written in Go, uses PASETO-based authentication, integrates Stripe for billing, and is deployed through a containerized CI/CD workflow.
Technologies Used
Key Highlights
Engineering Outcomes
- →Successfully designed, built, and operated a production SaaS application
- →Implemented subscription billing and secure authentication workflows
- →Maintained and evolved the system through multiple iterations
- →Owned architecture, deployment, and operational decision-making end-to-end
- →learnings: over-engineered for initial MVP, importance of customer feedback loops
Interested in Working Together?
Let's discuss how I can help with your data engineering needs.
Get In Touch